
II. Особенности алгоритмов быстрой обработки изображений
Для целей нашей статьи из всего многообразия алгоритмов быстрой обработки изображений мы возьмём только те, которые обладают такими характеристиками, как локальность, возможность распараллеливания и их относительная простота. Поясним более подробно, что мы имеем в виду:
- Локальность. Каждый пиксел вычисляется на основе ограниченного количества соседей.
- Высокая способность к распараллеливанию. Каждый пиксел не зависит по данным от других обработанных пикселей, что позволяет распараллелить процесс обработки.
- 16/32-битная точность арифметики. Как правило, при обработке изображений достаточно 32-битной вещественной (floating point) арифметики для обработки и 16-битного целочисленного типа данных для хранения.
1. Производительность
Как показывает практика, максимальной производительности можно добиться двумя способами — либо через увеличение аппаратных ресурсов, то есть с помощью наращивания количества процессоров, либо через оптимизацию программного кода. При сравнении возможностей графического процессора и центрального, в этом классе задач GPU выигрывает у CPU в соотношении цена/производительность, а реализация всего потенциала GPU возможна лишь при распараллеливании и тщательной многоуровневой оптимизации используемых алгоритмов.
2. Качество обработки изображений
Еще одним важным критерием является качество обработки изображений. Для одной и той же операции обработки изображений может существовать несколько алгоритмов, отличающихся ресурсоёмкостью и качеством получаемого результата
И тут важно понимать, что обычно ресурсоёмкие алгоритмы дают более качественный результат. Таким образом, многоуровневая оптимизация наиболее востребована для ресурсоёмких алгоритмов
После её выполнения сложные алгоритмы могут выдавать результат за приемлемое время, сравнимое со временем работы изначально быстрого, но более грубого алгоритма.
3. Латентность
Как уже говорилось выше, GPU имеет такую архитектуру, которая позволяет осуществлять параллельную обработку пикселов изображения, что приводит к сокращению латентности, или времени обработки одного изображения. Центральные процессоры обладают довольно скромными показателями латентности, поскольку в CPU параллелизм реализуется на уровне отдельных кадров, тайлов или строк изображений.
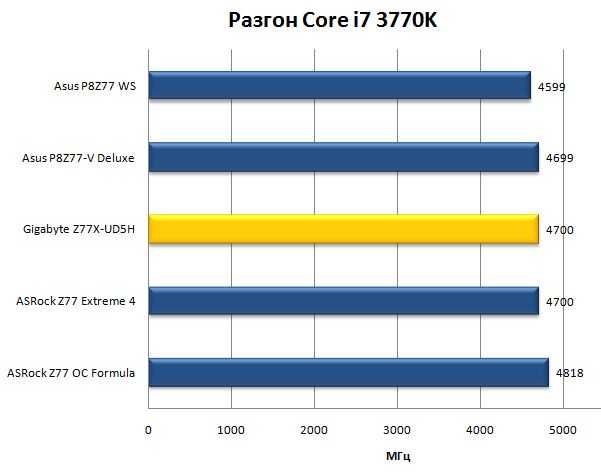
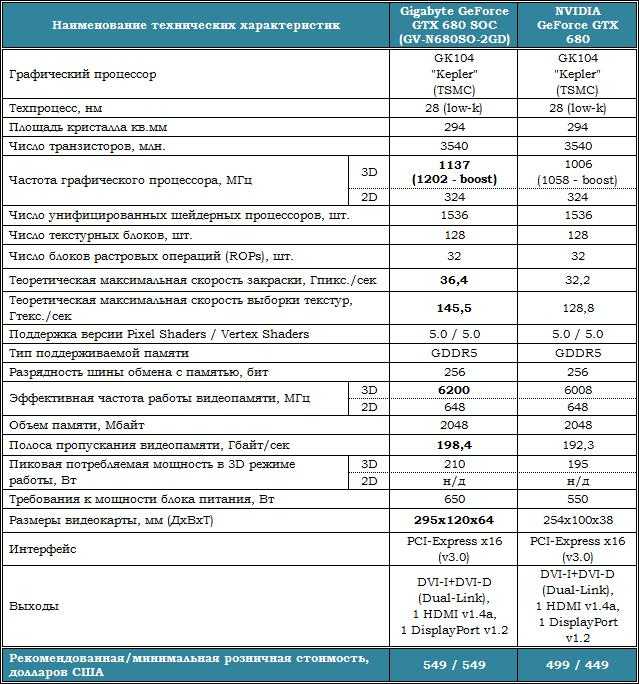
Обзор видеокарты
Продолжить обзор GTX 460 можно с описания внешнего вида устройства:
- Чёрный цвет платы, на которой расположены ее отдельные элементы, неплохо гармонирует с цветовым оформлением всего видеоадаптера;
- Система, отвечающая за охлаждение видеокарты, накрывает почти всю поверхность платы, не считая подсистему питания, хотя в процессе работы воздух от вентилятора всё равно на неё попадает;
- Длина платы достаточно большая для того, чтобы не мешать подключению к ней периферийных устройств – мониторов, проекторов, телевизоров.
Максимальное энергопотребление GTX 460 при полной загрузке достигает 160 Вт, что требует не только установки в слот PCI-e, но и дополнительного питания. Высокое значение TDP предполагает и наличие серьёзного охлаждения – из-за этого трубки выступают за пределы платы почти на 20 мм. Такой размер ограничивает установку карты внутри тонкого системного блока.
Какой блок питания нужен для GTX 460
Одним из главных параметров любого элемента ПК можно назвать его мощность, от которой зависят и характеристики блока питания десктопного компьютера. Как показывает практика владельцев видеокарты GTX 460, для неё достаточно 500-ваттного БП. В документации на видеоадаптер указана минимальная мощность в 450 Вт.
При выборе подходящего блока питания для компьютера с такой картой следует знать о необходимости ориентироваться не на указываемую производительность, а реальную. Настоящая мощность совпадает со значением из документации у качественных блоков с сертификатами 80 PLUS Gold. Показателей 500-ваттного БП хватит и для работы других устройств недорогого игрового ПК, который собирали на основе GTX 460 в начале 2010-х годов.
IV. Преимущества GPU над CPU
Наши лабораторные исследования показали, что при сравнении идеально оптимизированного софта для GPU и для CPU (с применением AVX2), преимущество GPU имеет глобальный характер: пиковые производительности CPU и GPU аналогичного года производства отличаются обычно на порядок для 32- и 16-битных типов данных. Также на порядок отличается и пропускная способность подсистемы памяти. В следующих пунктах мы рассмотрим эту ситуацию подробнее.
Если же использовать для сравнения софт для CPU без использования инструкций AVX2, то разница в производительности может достигать 50-100 раз в пользу GPU.
Все современные GPU оснащены разделяемой памятью, которая одновременно доступна всем «вычислителям» одного мультипроцессора, что, по сути, является программно-управляемым кэшем. Он идеально подходит для алгоритмов с высокой степенью локальности
Скорость доступа к этой памяти в несколько раз превосходит возможности L1 кэша CPU.
Ещё одной важной особенностью GPU по сравнению с CPU является то, что количество доступных регистров можно менять динамически (от 64 до 256 на один поток), тем самым позволяя снижать нагрузку на подсистему памяти. Для сравнения, в архитектурах x86 и х64 используется 16 универсальных регистров и 16 AVX регистров на один поток.
Наличие нескольких специализированных аппаратных модулей на GPU для одновременной работы над совершенно разными задачами: аппаратная обработка изображений (ISP) на Jetson, асинхронное копирование в GPU и обратно, вычисления на GPU, аппаратное кодирование и декодирование видео (NVENC, NVDEC), тензорные ядра для нейросетей, OpenGL, DirectX, Vulkan для визуализации.
Но, как результат всех перечисленных выше преимуществ GPU перед CPU, за всё это приходится платить высокими требованиями к параллельности алгоритмов. Если для максимальной загрузки CPU достаточно десятков потоков, то для полной загрузки GPU нужны десятки тысяч потоков.
Встраиваемые (embedded) приложения
Следует помнить и о таком типе задач, как встраиваемые решения. Здесь GPU уже конкурируют со специализированными устройствами, такими как FPGA (программируемая пользователем вентильная матрица) и ASIC (интегральная схема специального назначения). Основным преимуществом GPU перед прочими решениями является их существенно большая гибкость. Для отдельных встраиваемых решений GPU может быть серьёзной альтернативой, так как мощные многоядерные процессоры не проходят по допустимым требованиям к размеру и энергопотреблению.
Приложение №2 — алгоритмы memory-bound и compute bound
Когда мы говорим об этих типах алгоритмов, необходимо понимать, что речь идёт о конкретной реализации алгоритма на конкретной архитектуре. У каждого процессора есть некоторая пиковая арифметическая производительность. Если реализация алгоритма может на целевом участке достигнуть пиковой производительности процессора по вычислительным инструкциям, то тогда она compute-bound, в противном случае основным ограничением станет память и реализация memory-bound.
Подсистема памяти у всех процессоров является иерархической, состоящий из нескольких уровней. Чем уровень ближе к процессору, тем он меньше по объёму и тем он быстрее. На первом уровне находится кэш данных первого уровня, а на последнем уровне оперативная память.
Алгоритм может быть изначально compute-bound на первом уровне иерархии, а затем стать memory-bound на более высоких уровнях иерархии.
Рассмотрим несколько примеров. Допустим, мы хотим сложить два массива и записать результат в третий. Можно записать это как X = Y + Z, где X, Y, Z – массивы. Допустим, мы воспользуемся инструкциями AVX для реализации на процессоре. Тогда на один элемент нам потребуется два чтения, одно суммирование и одна запись. Современный CPU может выполнить два чтения и одну запись одновременно в кэш L1. Но вместе с тем, он может выполнить и две арифметические инструкции, а мы можем воспользоваться только одной. Это значит, что алгоритм суммирования массивов является memory-bound уже на первом уровне иерархии памяти.
Рассмотрим второй алгоритм. Фильтрация изображения в окне 3×3. Фильтрация изображения основана на операции свёртки окрестности пиксела с коэффициентами фильтра. Для вычисления свёртки используется инструкция MAD (или FMA в зависимости от архитектуры). Для окна 3×3 потребуется 9 таких инструкций. Операция инструкции B = AX + B, где B – аккумулятор, накапливающий значения свёртки, A – коэффициент фильтра, X – значение пиксела. Значения A и B находятся в регистрах, а значения пиксела загружаются из памяти. В этом случае на одну инструкцию FMA требуется одна загрузка. Здесь CPU сможет за счёт двух загрузок снабжать данными два порта FMA и полностью загрузит процессор. Алгоритм можно считать compute-bound.
Давайте рассмотрим этот же алгоритм на уровне доступа к оперативной памяти. Возьмём самую экономную по памяти реализацию, когда одно чтение пиксела обновляет все окна в которые он входит. В этом случае на одну операцию чтения будет приходиться 9 инструкций FMA. Таким образом, одно ядро CPU при обработке float данных на частоте 4 ГГц потребует 2 (инструкции за такт) × 8 (float в AVX регистре) × 4 (Байта в float) × 4 (ГГц) / 9 = 28.5 ГБайт/с. Двухканальный контролер с DDR4-3200 имеет пиковую пропускную способность в 50 ГБайт/с и по расчётам он способен быть источником данных только для двух CPU ядер в этой задаче. Поэтому такой алгоритм, запущенный на 8–16 ядерном процессоре является memory-bound. Несмотря на то, что на нижнем уровне он сбалансирован.
Теперь рассмотрим этот же алгоритм при реализации на GPU. Сразу видно, что GPU имеет на уровне SM менее сбалансированную архитектуру с уклоном в вычисления. Для архитектуры Turing отношение скорости арифметических операций (во float) к скорости загрузки из Shared Memory – 2:1, для Ampere 4:1. За счёт большего количества регистров на GPU можно реализовать указанную выше оптимизацию для CPU напрямую на регистрах GPU. Это позволяет сбалансировать алгоритм даже для Ampere. И на уровне Shared Memory реализация остается compute-bound. С точки зрения памяти верхнего уровня (глобальной) расчёт для Quadro RTX 5000 (Turing) даёт следующие результаты: 64 (операций за такт) × 4 (Байт в float) × 1.7 (ГГц) / 9 = 48.3 ГБайт/с на один SM. Отношение общей пропускной способности к пропускной способности SM составит 450 / 48.3 = 9.3 раза. Общее количество SM в Quadro RTX 5000 равно 48. Т.е. и для GPU алгоритм фильтрации на высоком уровне является memory-bound.

По мере роста размера окна алгоритм становится всё более сложным и соответственно смещается в сторону compute-bound. Большинство алгоритмов обработки изображений являются memory-bound на уровне глобальной памяти. И так как пропускная способность памяти GPU во многих случаях на порядок больше чем у CPU, то это обеспечивает сопоставимый прирост производительности.
Недостатки майнинга на видеокарте
Минусы добычи на видеокартах:
- Только три популярные криптовалюты (ETH, ETC, XMR) можно добывать на GPU. ASIC-майнеры захватывают все новые сети. А некоторые разработчики, опасаясь атаки 51%, переходят на такие алгоритмы, как RandomHash, доступные только для центральных процессоров.
- Сборка и запуск майнинг-фермы требует не только денежных затрат, но и профессиональных навыков. За процессом добычи нужно постоянно следить и периодически останавливать риг на профилактическое обслуживание.
Видеокарты работают тише, чем АСИК, но все же спать в одной комнате с майнинг-фермой сможет не каждый. Летом оборудование перегревается и требует дополнительного охлаждения, что снижает рентабельность добычи.
При том, что прибыльность такого дела довольно высока, существует несколько факторов, которые делают такое занятие сложным и проблематичным.
Даже если правильно выбрать оборудование, то высока степень зависимости то бесперебойного интернета и электричества. в последнем случае решение проблемы состоит в установке аккумуляторов и бесперебойников, а стабильность и надежность интернета завит от провайдера.
Зарабатывать на старых, слабых и дешевых компьютерах невозможно. Если компьютер слабый, то майнинг биткоинов не способен принести ощутимого результата. Важна мощность оборудования. И если вы решили заказать его из Китая, то следует соблюдать необходимые правила выбора, чтобы получить требуемый результат.
Майнинг оборудование издает сильный шум, а также нагревается в процессе работы. Из-за сильного нагрева кулеры вращаются сильнее, что и вызывает сильный шум. Оптимальным вариантом является использование помещения, оборудованного кондиционером.
Как мы тестируем
Тестирование продуктов, которые мы рекомендуем, является огромной частью общего процесса выбора в наших лучших руководствах. Это способ убедиться, что то, что мы рекомендуем, является самым лучшим вариантом в своей конкретной категории. Чтобы быть уверенным, что продукт является «лучшим», он должен показать отличные характеристики в наших тестах и показать лучшие качества по сравнению с конкурентами.
Большинство продуктов, которые мы рекомендуем здесь, прошли строгий процесс тестирования, который включает в себя все: от цены и внешнего вида до производительности и эффективности. Каждый продукт доведен до предела, чтобы увидеть, как он работает в условиях интенсивного стресса, чтобы убедиться, что он заслуживает первое место.
Это позволяет нам предоставить вам наиболее точный обзор того, как продукт работает, и, в конечном итоге, стоит ли он ваших кровно заработанных денег.
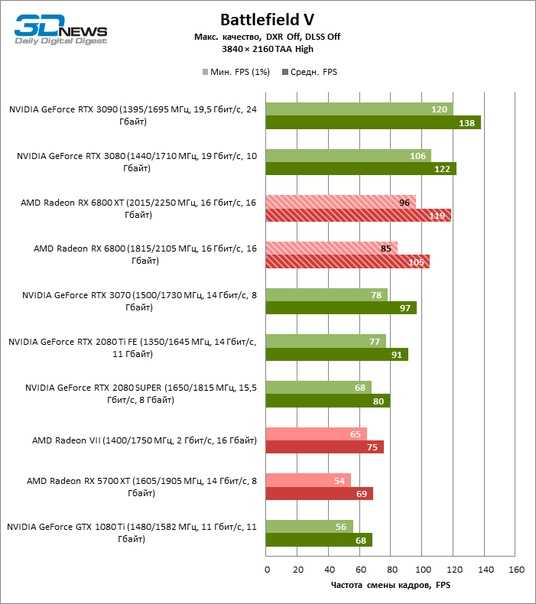
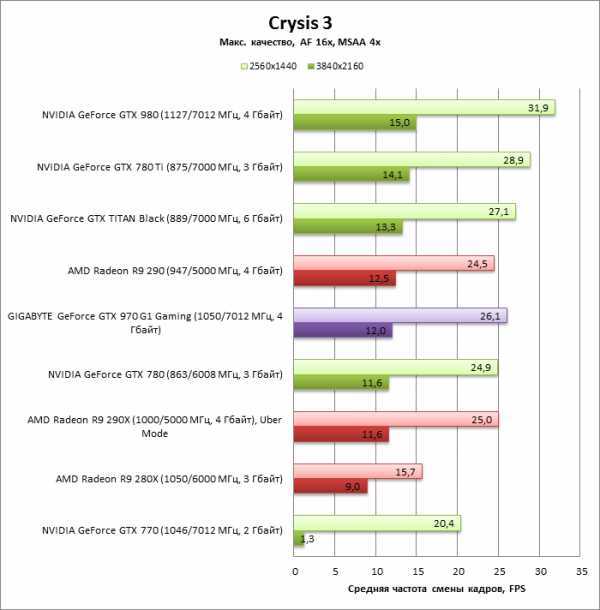
FullHD или 4k
Не секрет, что игрушки запущенные в FullHD и UHD Разрешениях по-разному нагружают ваше железо.
В UHD больше всего нагрузки получит видеокарта. При условии, что процессор у вас не самый старый и сможет нагрузить графический ускоритель по полной. Именно видеокарте придётся отрисовывать сложные и тяжеловесные кадры. Процессор же будет обсчитывать физику лишь для того количества кадров, которые смогла видать видеокарта.

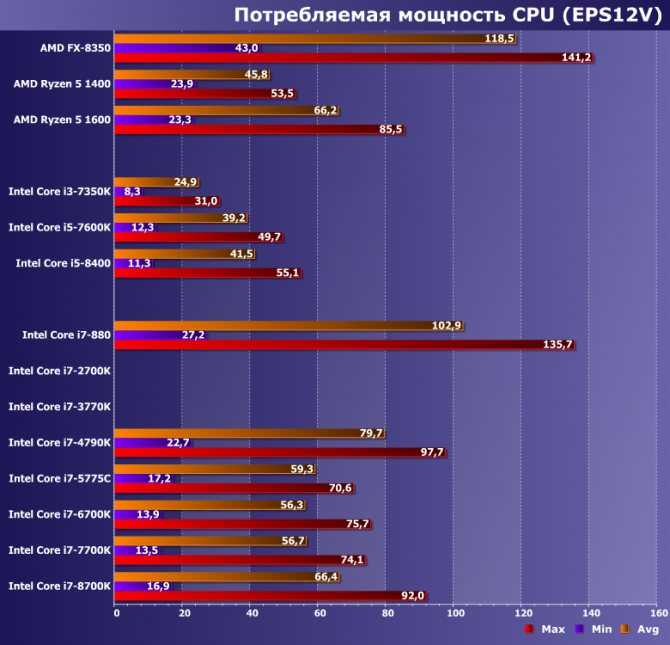

При игре в FullHD ситуация меняется. Здесь видеокарте становится проще, она успевает выдавать в разы большее количество кадров, потому и процессору задач тоже приваливает автоматически.
По сути мы получаем 2 типа игроков: UHD-фаны любят чёткую и максимально нашпигованную визуальными деталями картинку, а также чёткие шрифты. Приверженцы FHD ценят плавность игрового процесса и максимальное количество fps. Но для наслаждения такими вещами придётся ещё и игровой монитор прикупить с высокой частотой обновления и в идеале с низким временем отклика матрицы. Правда в случае высокого fps и достойного монитора, получается ещё один плюс по детализации. В динамике изображение будет менее мыльным за счёт более тщательной и быстрой отрисовки и возможности увидеть большее количество кадров.
Сегодня мы гоняем несколько игр, чтобы посмотреть, насколько сильно в них работают видеокарта и процессор, и как изменится ситуация, если процессор в систему поставить более современный. Для этого мы собрали два максимально близких друг к другу тестовых стенда, установили один и тот же билд Windows 10 и драйверов для видеокарты NVIDIA.
Компоненты получились следующие.
- Система охлаждения: be quiet! Dark Rock 4 Pro.
- Термоинтерфейс: Noctua NT-H2.
- Видеокарта: NVIDIA RTX 2080 Super FE.
- Оперативная память: Оперативная память: 2×IRDM PRO DDR4 8 Гб. @ 1800 MHz / 17-19-19-39.
- Системный накопитель данных: SSD NVMe Seagate Firecuda 510 1 Tb.
- Дополнительный SSD: Western Digital Blue 1Tb (WDS100T1B0A).
- Жёсткий диск: Toshiba HDWT360 6 TB.
- Звук: Creative Sound Blaster AE-7 + Samsung HW-Q60R + Samsung SWA-8500S.
- Wi-Fi модуль: TP-LINK Archer TX3000E.
- Системный блок: be quiet! DARK BASE PRO 900 со стоковыми вентиляторами.
- Блок питания: Be Quiet! Pure Power 11, 600W.
- Монитор: Philips 276E8V.
- Операционная система: Windows 10 Pro билд 19041.572.
- Версия видеодрайвера – 456.71. GeForce Experience – 3.20.5.48.
При втором тестировании материнская плата Asus Prime Z390-P сменилась на Asus ProArt Z490-CREATOR 10G и процессор i5-9600KF был заменён на i9-10900. Чуть позже мы надеемся повторить этот эксперимент, заменив видеокарту на RTX 30-й серии. Все остальные компоненты, в том числе и корпус остались неизменны при тех же настройках.
Вот та самая красотка от Asus.
В играх выбраны максимальные настройки графики, предусмотренные разработчиками. RTX и DLSS активны там, где они есть.
Приложение №3 Программные модели SIMD и SIMT, или почему у GPU так много потоков
Для повышения производительности CPU используются SIMD (single instruction, multiple data) инструкции. Одна такая инструкция позволяет выполнить несколько однотипных операций над вектором данных. Плюсом этого подхода является рост производительности без существенной модификации instruction pipeline. Все современные CPU, как x86, так и ARM, имеют SIMD инструкции. Минусом данного подхода является сложность программирования. Основной подход к SIMD программированию — это использование intrinsic. Intrinsic – это встроенные функции компилятора, которые содержат одну или несколько SIMD-инструкций, плюс инструкции для подготовки параметров. Intrinsic формируют низкоуровневый язык, очень близкий к ассемблеру, который крайне трудоёмок в использовании. Кроме того, для каждого набора инструкций у каждого компилятора есть свой набор Intrinsic. Выходит новый набор инструкций – нужно всё переписывать, переходим на новую платформу (с x86 на ARM) нужно переписывать, переходим на другой компилятор — опять нужно всё переписывать.
Программная модель для GPU называется SIMT (Single instruction, multiple threads). Одна инструкция синхронно исполняется в нескольких потоках. Этот подход можно считать развитием SIMD. Скалярная программная модель скрывает векторную суть машины, автоматизируя и упрощая многие операции. Именно поэтому для большинства программистов писать привычный скалярный код на SIMT проще, чем векторный на чистом SIMD.
CPU и GPU по-разному решают вопрос латентности инструкций при исполнении их на конвейере. Латентность инструкции – это через сколько тактов следующая инструкция может воспользоваться её результатами. Например, если латентность инструкции равна 3 и CPU может запускать 4 таких инструкции за такт, то за 3 такта процессор запустит 2 зависимых инструкции или 12 независимых. Чтобы избежать такого существенного простоя, все современные процессоры используют внеочередное исполнение инструкций. В этом случае процессор в заданном окне CPU анализирует зависимости инструкций и запускает независимые инструкции вне очереди.


GPU использует другой подход, основанный на многопоточности. У GPU есть pool потоков. Каждый такт выбирается один поток и из него выбирается одна инструкция, которая отправляется на исполнение. На следующем такте выбирается следующий поток и так далее. После того, как из всех потоков в pool была запущена одна инструкция, возвращаемся к первому потоку и т.д. Такой подход позволяет скрыть латентность зависимых инструкций за счёт исполнения инструкций из других потоков.
При программировании GPU можно условно выделить два уровня потоков. Первый уровень потоков отвечает за формирование SIMT. Для GPU NVIDIA – это 32 соседних потока, которые называются warp. Известно, что SM для Turing поддерживает 1024 потока. Это количество распадается на 32 настоящих потока, в рамках которых организуется SIMT исполнение. Настоящие потоки могут в один момент времени исполнять разные инструкции, в отличие от SIMT.
Таким образом, стриминговый мультипроцессор Turing – это векторная машина с размером вектора 32 и 32-мя независимыми потоками. Ядро CPU с AVX – это векторная машина с размером вектора 8 и двумя независимыми потоками.
Скорость глубокого обучения GPU в пересчёте на стоимость
- Использование предварительно обученных трансформеров, или обучение небольшого трансформера с нуля >= 11 ГБ.
- Обучение большого трансформера или свёрточной сети в исследовании или продакшене: >= 24 ГБ.
- Прототипирование нейросетей (трансформера или свёрточной сети) >= 10 ГБ.
- Участие в конкурсах Kaggle >= 8 ГБ.
- Компьютерное зрение >= 10 ГБ.
Рис. 3: нормализованное быстродействие в пересчёте на доллары по отношению к RTX 3080.Рис. 4: нормализованное быстродействие в пересчёте на доллары по отношению к RTX 3080.Рис. 5: нормализованное быстродействие в пересчёте на доллары по отношению к RTX 3080.
Понимание спецификаций
Один из лучших способов узнать, подходит ли видеокарта RTX 3060 для ваших нужд, — это сначала понять технические характеристики, которыми она оснащена. Понимание спецификаций не только дает вам лучшее представление о том, что предоставляет графический процессор (с точки зрения производительности), но и поможет вам ответить на любые вопросы, которые могут у вас возникнуть относительно того, подходит ли он вам.
Имея это в виду, ниже мы рассмотрим некоторые из базовых спецификаций, которые повлияют на общую производительность графического процессора:
Тактовая частота
Тактовая частота, часто называемая тактовой частотой, — это единица измерения, которая определяет, насколько быстро работает микропроцессор в графическом процессоре. Хотя это напрямую не связано с общей производительностью, оно дает нам приблизительное представление о том, насколько быстро ваш графический процессор может отображать графику и читать инструкции.
Каждый графический процессор поставляется с заводскими базовыми часами, которые часто используются, когда компьютер находится в состоянии ожидания. Однако AIB могут повысить дополнительную производительность графического процессора, оснастив его тактовой частотой ускорения и тактовой частотой игры. Это разогнанные скорости, которые срабатывают, когда вашему ПК требуется дополнительная производительность под нагрузкой. Одна из причин, по которой многие AIB отличаются, — это разогнанные скорости — так что следите за этим.
VRAM
VRAM, возможно, является наиболее распространенной спецификацией, которую вы увидите при покупке графического процессора. Он часто маркируется на боковой стороне коробки и используется в качестве маркетингового метода по сравнению с другими графическими процессорами.
VRAM напрямую влияет на то, насколько хорошо ваш графический процессор может выполнять задачи, связанные с производительностью. Он также определяет, насколько хорошо ваш компьютер может отображать и воспроизводить форматы с высоким разрешением, при этом 4K является наиболее интенсивным на сегодняшнем рынке.
Тип памяти
Одно из основных различий, которое мы наблюдали за последние пару лет, связано с сектором памяти графического процессора. Типы памяти эволюционировали в течение многих лет, и последним предложением стала GDDR6 — Graphics Double Data Rate Type Six. Этот тип памяти специально разработан для использования в графических процессорах и используется так же, как и ваша системная оперативная память.
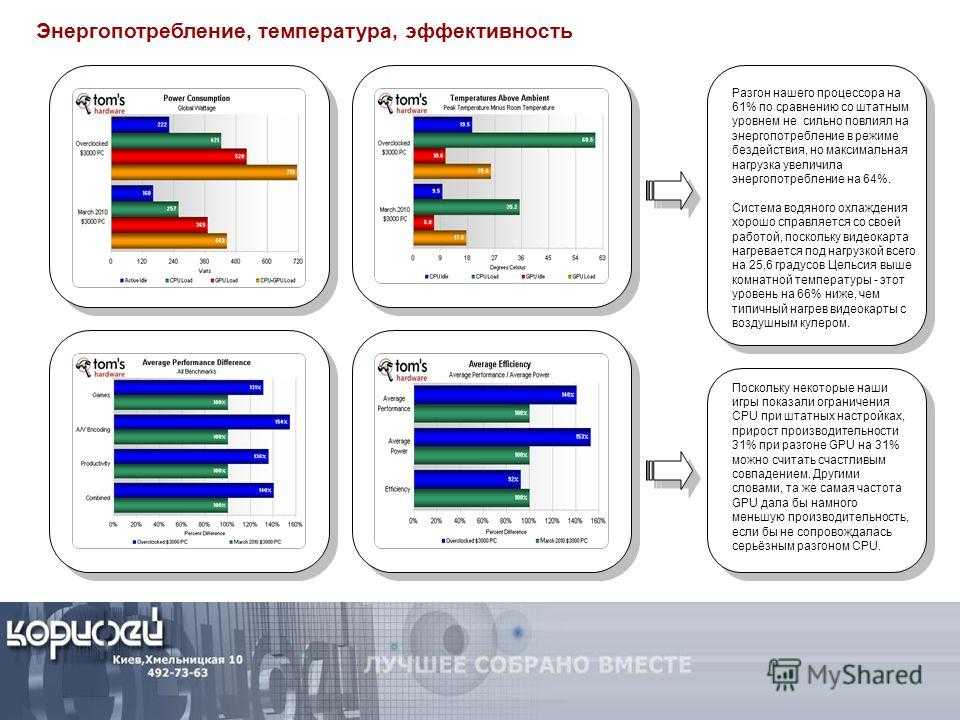

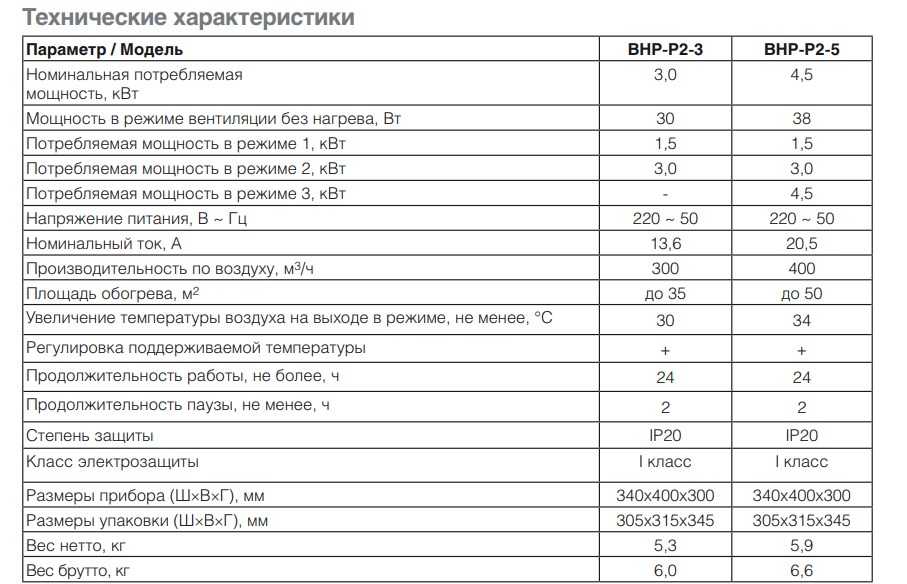
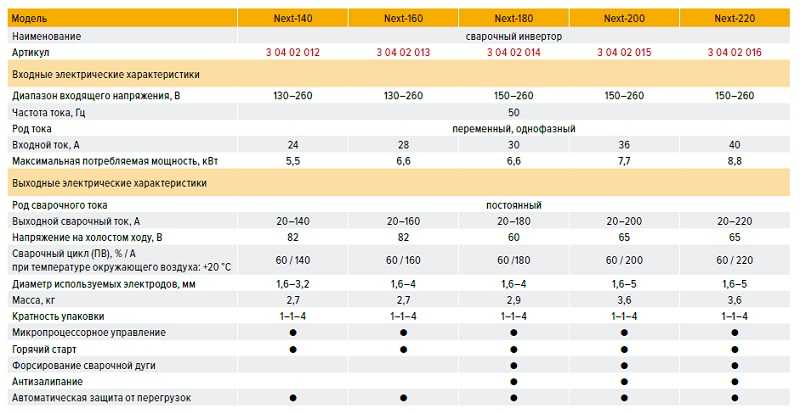
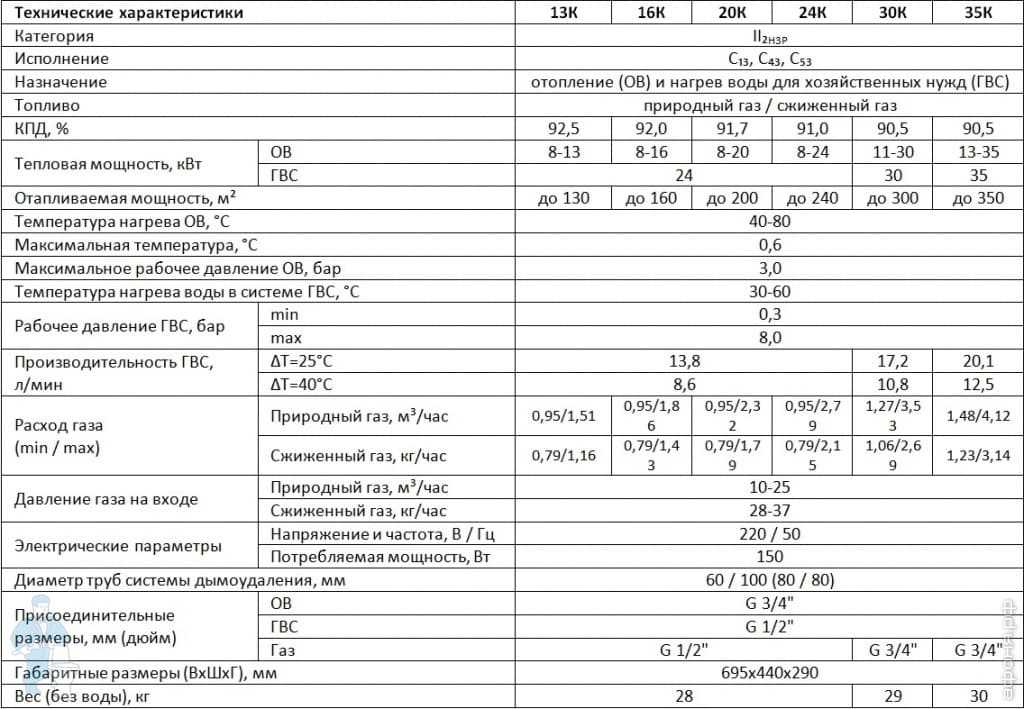
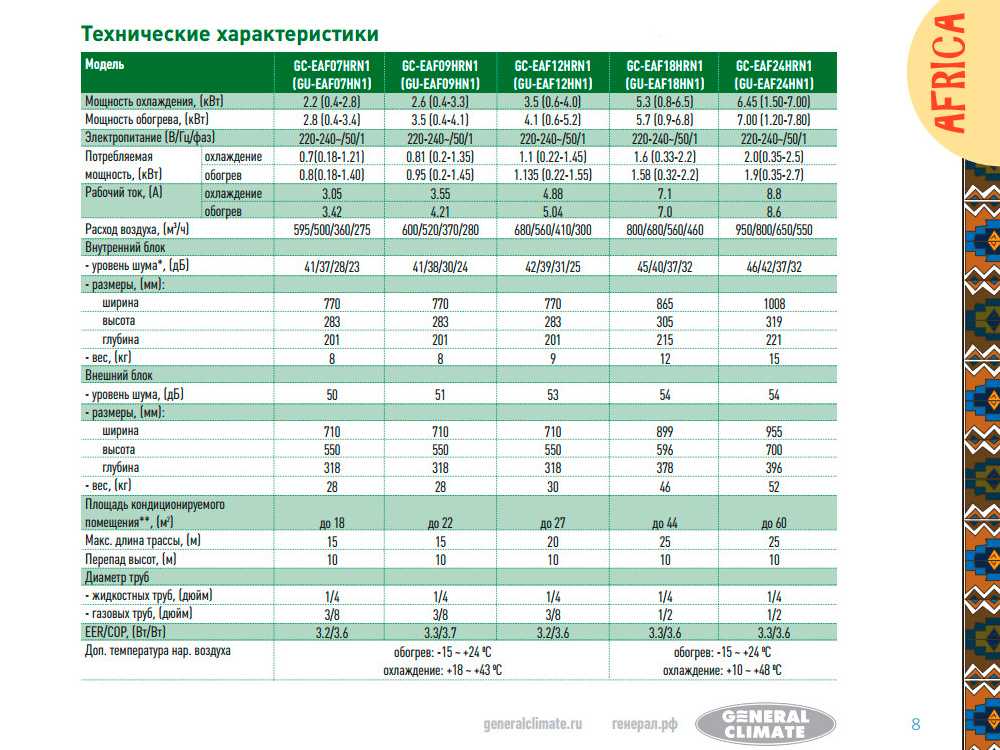

Последняя версия этого ОЗУ графического процессора работает с увеличенной пропускной способностью, потребляя при этом меньше энергии — нормальный процесс для большинства модулей ОЗУ. Хотя все видеокарты AIB RTX 3060 имеют один и тот же тип памяти, это все же стоит знать, поскольку другие графические процессоры не будут предлагать такую эффективную SDRAM.
Что в итоге?
Результаты получаются индивидуальными под каждую игру, которую вы можете захотеть запустить на своей системе. Но в большинстве случаев, если у вас процессор Intel не ниже 9 поколения линейки i5, его хватит для того, чтобы узким местом сборки стала именно видеокарта, если вы ещё не успели приобрести себе RTX 30-й серии или не владеете хотя бы RTX 2080 Ti. Апгрейд процессора, как видно, даёт во многих случаях ощутимый прирост fps, что оценят те, кто хочет играть на высокочастотном мониторе. Но если выбираете для себя 4K-гейминг, то к Новому году стоит задумываться о прокачке видеокарты.
Если вам интересны новости мира ИТ также сильно, как нам, подписывайтесь на наш Telegram-канал. Там все материалы появляются максимально оперативно. Или, может быть, вам удобнее или ? Мы есть также в .