
Введение или о чипах FPGA в 3-х абзацах
Микросхема FPGA (англ. field-programmable gate array), она же программируемая пользователем вентильная матрица (ПЛИС), — это интегральная микросхема (ИМС), которую можно реконфигурировать под любые сложные вычислительные задачи. В индустрии существует потребность в специализированных микросхемах (ASIC, application-specific integrated circuit, «интегральная схема специального назначения») — от управления космическими аппаратами и до расчетов по финансовым моделям. Однако до появления FPGA сильным и одновременно слабым местом специализированных ИМС была жесткая функциональность, заложенная в микросхему, а также высокая сложность проектирования и стоимость запуска в производство. Если функционал затем требовалось потом хоть чуть-чуть изменить, или на этапе проектирования произошли ошибки, то нужно было создавать по сути новую ИМС.
FPGA-ускоритель с чипом Intel Altera Arria 10 и портами 10GE
Появление на рынке FPGA-ускорителей, которые можно перепрограммировать сколь угодное число раз, причем на языке высокого уровня типа С, стало настоящим прорывом в нише высокопроизводительных вычислений. Это позволило ускорить время разработки, время выхода продуктов на рынок. Появились совершенно новые возможности для разработчиков аппаратных средств, в т.ч. работающих над программированием специализированных интегральных схем типа ASIC.
FPGA-процессоры прошли уже 2 этапа с точки зрения доступности этой технологии и сегодня активно входят в третий этап. Первые FPGA появились в 1985 году, но их программирование по-прежнему требовало знания языка низкого уровня типа ассемблера. На втором этапе, который начался примерно в 2013 году, и благодаря усилиям компании Altera, появилась возможность программирования на С-подобном языке высокого уровня. Это кардинально расширило применимость FPGA, но высокая стоимость чипов по-прежнему сдерживала расширение круга клиентов, которые могли бы себе позволить эту технологию.
Традиционно маршрут проектирования и верификации ПЛИС крайне трудоемок и требует высокой специализации, по своей сложности маршрут приближается к проектированию ASIC. Это ограничивает использование ПЛИС разработчиками. Особенно это касается вычислительных приложений, где участники процесса, — программист, математик, алгоритмист, — желают сфокусироваться на своей задаче, а не на ее аппаратной реализации. Решая эту проблему, компания Altera в 2013 году вывела на рынок для своих ПЛИС поддержку открытого стандарта программирования гетерогенных вычислительных платформ OpenCL, что расширило возможность применения аппаратуры разработчиками вычислительных приложений, не знакомых (малознакомых) с аппаратурой ПЛИС, языками HDL, маршрутом проектирования и верификации. Но, осталась проблема – дорогостоящая аппаратура и средства проектирования.
И, наконец, где-то с 2016 года можно говорить о третьем этапе, который ознаменовался доступностью для широкого круга клиентов полностью готовых серверов (физических и виртуальных) с FPGA-процессорами в облаках крупнейших дата-центров — Amazon Web Services (AWS), Cloud Alibaba и Huawei Cloud. В России впервые выделенные серверы с FPGA-процессорами стали доступны в дата-центре Selectel с 2017 года.
Что ещё следует учесть в случае с Ampere / RTX 30
- Ampere позволяет проводить обучение сетей на основе разреженных матриц, что ускоряет процесс обучения максимум в два раза.
- Разреженное обучение сетей до сих пор редко используется, однако благодаря ему Ampere не скоро устареет.
- У Ampere есть новые типы данных с малой точностью, благодаря чему использовать малую точность гораздо проще, однако это не обязательно даст прирост в скорости по сравнению с предыдущими GPU.
- Новый дизайн вентиляторов хорош, если между GPU у вас есть свободное место – однако непонятно, эффективно ли будут охлаждаться GPU, стоящие вплотную.
- 3-слотовый дизайн RTX 3090 будет проблемой для сборок по 4 GPU. Возможные решения – использовать 2-слотовые варианты или расширители для PCIe.
- Четырём RTX 3090 потребуется больше питания, чем может предложить любой стандартный БП на рынке.
ASUS ENGTX460 DirectCU TOP/2DI/768MD5
ASUS ENGTX460 DirectCU TOP/2DI/768MD5
Цена $245
Хорошая СО; качественное исполнение; утилита для поднятия напряжения на GPU
Не обнаружено
Вердикт
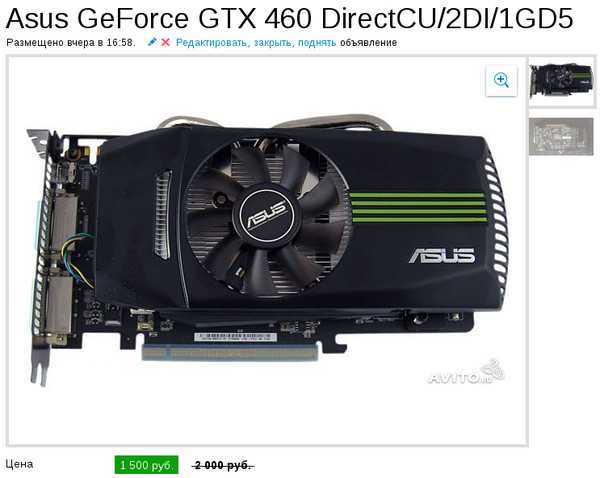
В отличие от старшей модели в ENGTX460 DirectCU TOP/2DI/768MD5 в кулере используются две (а не три) тепловые трубки и применяется более короткий радиатор. Однако из-за сравнительно низкой частоты работы и «урезанного» чипа греется и шумит рассматриваемая карта меньше, чем одногигабайтовая версия. Кроме того, по абсолютным показателям она оказалась самой «холодной» среди протестированных моделей. Как и в старшем продукте, печатная плата усилена ребром жесткости, силовая подсистема накрыта радиатором, а разъемы для дополнительного питания находятся на торце РСВ, что весьма удобно. Для обеих моделей ASUS ENGTX460 DirectCU подобное решение является несомненным преимуществом, так как кожух СО заметно длиннее PCB. Правда, в TOP/2DI/1GD5 это было обусловлено размером радиатора, тогда как здесь увеличение габаритов кулера – маркетинговый ход.
Продукт предоставлен MTI
Что такое GPU-ускорение на Android
Сама аббревиатура GPU на смартфонах расшифровывается точно так же, как и на других устройствах, включая компьютеры, и означает «Графический процессор». Поэтому при активации ускорения вся нагрузка телефона переходит с ЦПУ на видеокарту, едва ли задействованную в повседневных задачах.
Главное назначение GPU-ускорения заключается в принудительном переносе рендеринга с процессора устройства на GPU с целью повышения производительности. Как правило, особенно если брать в расчет современные мощные смартфоны или планшеты и весьма требовательные игры, подобная возможность положительно повлияет на скорость обработки информации. Кроме того, на некоторых телефонах можно получить доступ к дополнительным настройкам рендера.









Иногда ситуация может быть полностью противоположной, в связи с чем включение принудительного рендеринга двухмерного рисования может стать причиной невозможности запуска того или иного приложения. Так или иначе, функцию можно включать и отключать без ограничений, что делает большинство проблем легко разрешимыми. К тому же, как можно понять по вышесказанному, большинство приложений все же отлично работают при включенном GPU-ускорении, позволяя использовать ресурсы устройства на максимум.
Ускорение роботы
Если знать, как ускорить работу gpu на android и что это, результат обычно проявляется моментально. Если этого не произошло, на всякий случай нужно провести перезагрузку смартфона. После включения аппарата скорость становится заметно выше.
Грамотно проведенные настройки повышают производительность встроенного графического ускорителя. Благодаря этому анимации и отображающаяся на дисплее информация будут представлены в высокой четкости и яркости. При запуске подобного ускорителя следует быть готовым к тому, что время автономной работы снизится в среднем на 20%.
Аппаратное ускорение
Пропустить возможность установки требуемого обновления сложно. На дисплее постоянно висит напоминание об этом. Несмотря на то, что вина лежит на разработчике Google, организация не смогла серьезно увеличить функциональный механизм производимых обновлений.
Обновлением программы на устройстве пренебрегать не рекомендуется. В реальности правильно проведенное аппаратное обновление позволит устранить определенные ошибки и внести элементы увеличения уровня производительности. Чтобы использовать гаджет, работающий на ОС Андроид, полноценно, необходимо всегда следить за тем, чтобы в распоряжении была последняя версия.
Рейтинг процессоров 2020: бюджетные модели
AMD Ryzen 3 2200G, Ryzen 5 1600, Intel Core i3-9100F
Самые простые модели игровых процессоров можно получить в свое распоряжение за совсем небольшую сумму. Так, например, Ryzen 3 2200G обойдется вам всего лишь в 5500 рублей. Это отличная модель, которая имеет на борту встроенную графику Radeon Vega 8. Для сравнения: встройка отстает от GT 1030 на 30-40%. Мы согласны, что это очень большая разница. Да и GT 1030 — далеко не игровая видеокарта, но начать сборку первого бюджетного компьютера с последующим апгрейдом комплектующих с Ryzen 3200G — это хороший выбор. Тем более, что за такую низкую стоимость вы получите еще и боксовый кулер в комплекте. Базовая частота модели составляет 3,5 ГГц, а в бусте достигает 3,7 ГГц.
Кстати, не забудьте подобрать под этот камень соответствующую материнскую плату, которая будет иметь нужный вам видео-выход. Не все материнские платы на сокете АМ4 обладают видео-интерфейсами!
4 ядра и 4 потока для современных игр, конечно, недостаточно, но насладиться нетребовательными проектами у вас всё же получится. Если посмотреть в сторону конкурентов, то мы в этой весовой категории увидим модель i3-9100F. И это тоже неплохой вариант. Особенно в том случае, если у вас есть дискретная видеокарта. Этот процессор на 15-20% производительнее, но также обладает 4 ядрами и 4 потоками.
Если доплатить всего 1500 рублей, то можно встретить Ryzen 5 1600, который будет иметь уже 6 ядер и 12 потоков. Первое поколение процессоров от AMD сильно упало в цене, хотя обладает неплохими техническими характеристиками. По производительности данная модель проигрывает около 20% по сравнению с i3-9100F. Но это только в рамках нагрузки на 2-4 ядра. В играх, которые способны задействовать 8 и более потоков, «красный» процессор опережает конкурента на целых 40-50%. А излюбленное блюдо современных ААА-игр — это именно большое количество потоков, которые способны параллельно обрабатывать много информации.
Все в небо! Ближе к облакам!
- При этом обучение нейросети относительно слабо масштабируется горизонтально. Т.е. мы не можем взять 1000 мощных компьютеров и получить ускорение обучения в 1000 раз. И даже в 100 не можем (по крайней мере пока не решена теоретическая проблема ухудшения качества обучения на большом размере батча). Нам вообще довольно сложно что-то раздавать по нескольким компьютерам, поскольку как только падает скорость доступа к единой памяти, в которой лежит сеть — катастрофически падает скорость ее обучения. Поэтому если у исследователя будет доступ к 1000 мощных компьютеров
на халяву, он, безусловно, скоро их все займет, но скорее всего (если там не infiniband + RDMA) обучаться там будет много нейросетей с разными гиперпараметрами. Т.е. общее время обучения будет лишь в несколько раз меньше, чем при 1 компьютере. Там возможны и игра с размерами батча, и дообучение, и прочие новые модные технологии, но основной вывод — да, при увеличении количества компьютеров эффективность работы и вероятность достичь результата будут расти, но не линейно. Причем сегодня время исследователя Data Science стоит дорого и часто если можно потратить много машин (пусть неразумно), но получить ускорение — это делается (см. пример с 1, 2 и 4 дорогими V100 в облаках чуть ниже).
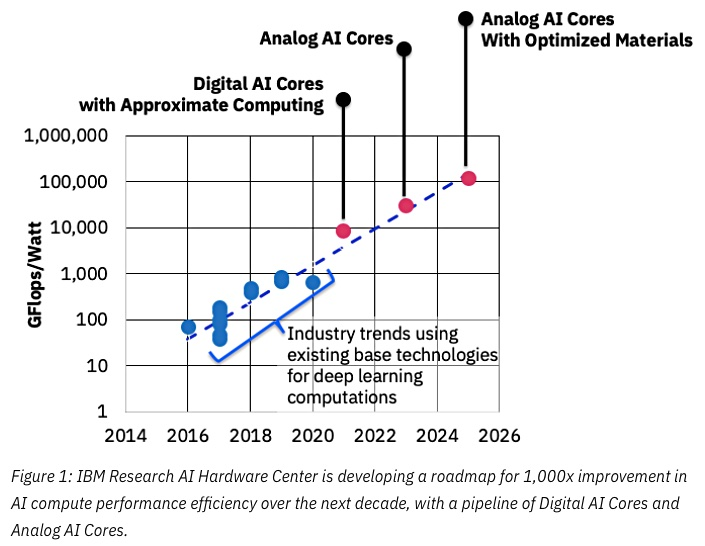
Облачные вычисления на FPGA
Облачные сервисы FPGA появились как ответ на высокую стоимость плат ускорителей с чипом FPGA. В этом случае клиентам предлагаются в аренду физические и/или виртуальные серверы с установленными в них FPGA-ускорителями. Как правило, это партнерский продукт от производителя (например, Intel) и дата-центра как провайдера IaaS-услуг.
FPGA-сервер с ускорителем от «Алмаз-СП» можно бесплатно протестировать в дата-центре Selectel
Одним из решений проблемы доступности технологии для массового применения видится возможность аренды вычислительных мощностей на базе FPGA. В Selectel услуга предполагает получение доступа к серверу с установленным ускорителем линейки Euler производства компании Euler Project на базе Intel Arria 10 FPGA. На сервере развернуты необходимые SDK и BSP для разработки, отладки и компиляции OpenCL-ядер, средства разработки для написания хост-приложений (Visual Studio). В качестве ознакомительной демонстрации предлагается рассмотренный ранее пример с построением множества Мандельброта: проект предоставляется в исходных кодах и настроен для компиляции.
Euler Project для всех желающих проводит учебный курс по программированию на OpenCL для FPGA. Данный курс разработан специально для российской аудитории: инженеров, научных сотрудников, студентов технических ВУЗов. Он вобрал в себя материал официальных тренингов Intel и дает возможность пошагового изучения технологии от сборки простейшего приложения до применения специфических методов оптимизации, порой совершенно необходимых для достижения оптимального быстродействия.








В таком виде FPGA-технология становится более привлекательной для клиентов, так как им уже не нужно приобретать непосредственно «железо», а капитальные расходы заменяются на операционные. Соответственно, значительно расширяется круг компаний, которые могут позволить себе использование расчетов на FPGA-ускорителях для своих проектов.
Железный сайт
Введение
Собираетесь сменить свою видеокарту? Тогда Вам будет интересен сегодняшний обзор видеокарты с поддержкой последних технологий, таких как DirectX 11 и Shader Model 5.0. Это модель ENGTX460 TOP от Asus, которая основана на графическом процессоре GTX 460 от NVIDIA. Однако ASUS увеличили тактовые частоты ядра до 775 МГц, а памяти до 1000 МГц по сравнению с референсной картой. Также производитель улучшил охлаждение видеокарты и увеличил напряжения, чтобы обеспечить стабильность в работе. На видеокарте установлено охлаждение DirectCU, основная особенность которого заключается в прямом контакте тепловых трубок с поверхностью GPU. Это позволяет более эффективно охлаждать чип. Интересно, как будет выглядеть видеокарта в игровых приложениях. Это мы выясним немного позже, а сейчас осмотр видеокарты Asus ENGTX460 TOP.
Осмотр видеокарты
На лицевой стороне коробки Asus TOP ENGTX460 Вы увидите логотип ASUS с рекламным слоганом в верхнем левом углу. Большую часть коробки занимает изображение какого-то мифического создания. Слева под логотипом ASUS Вы можете прочесть надпись «115% Speed Overclocked», которая гласит, что видеокарта имеет «разгон из коробки». Фабричный разгон — это особенность, которая характерна для видеокарт среднего ценового диапазона, и рассчитана на потребителя, который не хочет вникать в тонкости разгона, а хочет купить и играть. Конечно, на коробке Вы найдете название ENGTX460 TOP, напечатанное крупным шрифтом, а под ним перечень особенностей видеокарты: DirectCU, 1 Гб DDR5, разгон до 775 МГц, полная поддержка DirectX и ядро GTX 460. На обратной стороне коробки Вы найдете изображение, которое демонстрирует Вам преимущества модели TOP по сравнению с референсным образцом, такие как тонкая настройка Voltage tweak и DirectCU. Наверху перечислены особенности видеокарты, а в правой части рекомендуемые системные требования.

Когда Вы откроете упаковку, Вы увидите коробку черного цвета с золотистым логотипом ASUS. В ней два отделения, одно поменьше, где хранятся дополнительные аксессуары, а второе большое для видеокарты. Чтобы избежать повреждения при транспортировке, видеокарта плотно упакована в пеноплиэтилен.

В комплектацию видеокарты входят переходник питания с 4 pin molex на PCI-E, переходник DVI — D-Sub, DVI — HDMI, бумажник для CD и руководство по установке. В комплекте отсутствует CD диск с драйверами. Пока видеокарта дойдет до потребителя, уже выйдут обновленные версии драйверов, которые необходимо будет загрузить из сети. Только этим можно объяснить решение Asus не включать в комплект диск с драйверами.

Теперь после осмотра упаковки и комплектации, перейдем непосредственно к осмотру самой видеокарты ASUS ENGTX460 TOP.
Предыдущая — Следующая >>
Архитектура
В обзорах, посвященных выходу того или иного поколения центральных процессоров, авторы то и дело констатируют, что разница в производительности в х86-вычислениях год от года составляет мизерные 5-10%. Это своеобразная традиция. Ни у AMD, ни у Intel уже давно не наблюдается серьезного прогресса, а фразы в стиле «продолжаю сидеть на своем Sandy Bridge, подожду следующего года» становятся крылатыми. Как я уже говорил, в играх процессору тоже приходится обрабатывать большое количество данных. В таком случае возникает резонный вопрос: в какой степени эффект процессорозависимости наблюдается в системах с различными архитектурами?
Gigabyte GV-N460OC-1GI
GIGABYTE GeForce GTX460 GV-N460OC-1GI Видеокарты на
Уведомить о появлении в продаже
Цена $250
Тихая и эффективная система охлаждения; повышенные частоты
Не обнаружено
Вердикт

Компания Gigabyte оснастила видеокарту GV-N460OC-1GI
кулером собственной разработки. Вентиляторы, использующие «антитурбулентный дизайн лопастей», продувают ребра радиатора, нанизанного на две медные тепловые трубки. Рассматриваемая СО действительно хорошо справляется со своей задачей и при этом остается весьма тихой в работе. Как и в большинстве современных материнских плат производства Gigabyte, в данной карте используются утолщенные токопроводящие слои в PCB, что должно улучшить энергоэффективность и температурный режим.








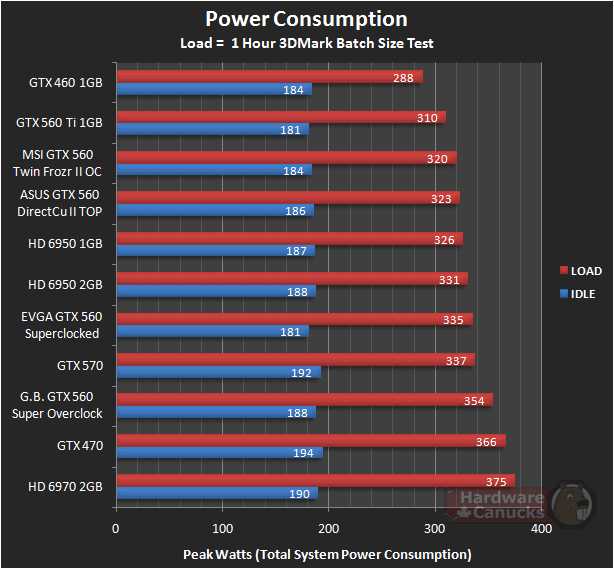

Производитель повысил показатели рассматриваемой модели относительно рекомендованных на достаточно скромное значение, но, продолжив его начинание, можно добиться вполне достойных результатов – в нашем случае покорились 828 МГц для ядра и 4480 МГц эффективной частоты для памяти.
Продукт предоставлен Gigabyte
Структура
В зависимости от назначения СнК может оперировать как цифровыми сигналами, так и аналоговыми, аналого-цифровыми, а также частотами радиодиапазона — все на одной подложке чипа. СнК широко распространены на рынке мобильной электроники из-за низкого энергопотребления. Обычно применяются в сфере встроенных систем.
Разница с микроконтроллером довольно мала. Микроконтроллеры обычно имеют менее 100 кб оперативной памяти (обычно даже несколько килобайт) и часто на самом деле являются системами-на-кристалле, в то время как термин СнК используется для более мощных процессоров, способных запускать программы вроде настольных версий Windows и Linux, которым требуется внешняя память (флеш или оперативная) для полезной работы и которые могут быть использованы с различными внешними переферийными устройствами. Вкратце, для больших систем, термин Система на кристалле — это гипербола, показывающая скорее техническое направление нежели реальность: высокую степень интеграции схем, ведущая к снижению производственных цен и производства малых систем. Многие системы являются слишком сложными, чтобы уместиться на одном кристалле, построенным на процессоре, оптимизированным на выполнение только одной из множества задач систем. ста́льная систе́ма (англ. System-on-a-Chip, SoC (произносится как «эс-оу-си»)) — в микроэлектронике — электронная схема, выполняющая функции целого устройства (например, компьютера) и размещенная на одной интегральной схеме. В зависимости от назначения она может оперировать как цифровыми сигналами, так и аналоговыми, аналого-цифровыми, а также частотами радиодиапазона — все на одной подложке чипа. СнК широко распространены на рынке мобильной электроники из-за низкого энергопотребления. Обычно применяются в сфере встроенных систем.
Разница с микроконтроллером довольно мала. Микроконтроллеры обычно имеют менее 100 кб оперативной памяти (обычно даже несколько килобайт) и часто на самом деле являются системами-на-кристалле, в то время как термин СнК используется для более мощных процессоров, способных запускать программы вроде настольных версий Windows и Linux, которым требуется внешняя память (флеш или оперативная) для полезной работы и которые могут быть использованы с различными внешними переферийными устройствами. Вкратце, для больших систем, термин Система на кристалле — это гипербола, показывающая скорее техническое направление нежели реальность: высокую степень интеграции схем, ведущая к снижению производственных цен и производства малых систем. Многие системы являются слишком сложными, чтобы уместиться на одном кристалле, построенным на процессоре, оптимизированным на выполнение только одной из множества задач систем.
Если разместить все необходимые цепи на одном полупроводниковом кристалле не удается, применяется схема из нескольких кристаллов, помещенных в единый корпус (англ. System in a package, SiP). SoC считается более выгодной конструкцией, так как позволяет увеличить процент годных устройств при изготовлении и упростить конструкцию корпуса.
Типичная SoC содержит:
- один или несколько микроконтроллеров, микропроцессоров или ядер цифровой обработки сигналов(DSP). SoC, содержащий несколько процессоров, называют многопроцессорной системой на кристалле(MPSoC).
- банк памяти, состоящий из модулей ПЗУ, ОЗУ, ППЗУ или флеш.
- источники опорной частоты, например, кварцевые резонаторы и схемы ФАПЧ (фазовой автоподстройки частоты),
- таймеры, счётчики, цепи задержки после включения,
- блоки, реализующие стандартные интерфейсы для подключения внешних устройств: USB, FireWire,Ethernet, USART, SPI.
- блоки цифро-аналоговых и аналого-цифровых преобразователей.
- регуляторы напряжения и стабилизаторы питания.
СнК, построенная на микропроцессоре.
В программируемые SOC часто входят также блоки программируемых логических матриц — ПЛМ; а в прогреннаммируемые аналого-цифровые SOC — еще и программируемые аналоговые блоки.
Блоки могут быть соединены с помощью шины собственной разработки или стандартной конструкции, например, AMBA в чипах компании ARM. Если в составе чипа есть контроллер прямого доступа к памяти (ПДП), то с его помощью можно заносить данные с большой скоростью из внешних устройств напрямую в память чипа, минуя процессорное ядро.
Palit GeForce GTX 460 Sonic 1024MB
Palit GeForce GTX 460 Sonic 1024MB
Цена $239
Компактные размеры; потенциал разгона; повышенные частоты
Температурный режим и уровень шума отставляют желать лучшего
Вердикт
Серия видеокарт Sonic от Palit пользуется заслуженным признанием у экономных оверклокеров благодаря демократичным ценам, неплохим СО и потенциалу для разгона. К сожалению, в этот раз модель Palit выделяется лишь за счет частотной формулы, и то с оговоркой – максимальные показатели для памяти могли бы быть и выше. Фактор стоимости в данном случае не окажет значительного влияния на решение потребителя, ведь цена устройства – на уровне более интересных карт от соперников. Существенные нарекания у нас вызвал используемый кулер. В отличие от продукции конкурентов, где активно применяются тепловые трубки, его конструкция проста: радиатор вырезан из бруска алюминия. В итоге эффективность охлаждения в целом невысока. Несмотря на то что частоты у Palit GeForce GTX 460 Sonic 1024MB были увеличены несущественно, ядро греется весьма ощутимо. Вентилятор же создает повышенный шум в работе.
Продукт предоставлен Palit
Приложение №3 Программные модели SIMD и SIMT, или почему у GPU так много потоков
Для повышения производительности CPU используются SIMD (single instruction, multiple data) инструкции. Одна такая инструкция позволяет выполнить несколько однотипных операций над вектором данных. Плюсом этого подхода является рост производительности без существенной модификации instruction pipeline. Все современные CPU, как x86, так и ARM, имеют SIMD инструкции. Минусом данного подхода является сложность программирования. Основной подход к SIMD программированию — это использование intrinsic. Intrinsic – это встроенные функции компилятора, которые содержат одну или несколько SIMD-инструкций, плюс инструкции для подготовки параметров. Intrinsic формируют низкоуровневый язык, очень близкий к ассемблеру, который крайне трудоёмок в использовании. Кроме того, для каждого набора инструкций у каждого компилятора есть свой набор Intrinsic. Выходит новый набор инструкций – нужно всё переписывать, переходим на новую платформу (с x86 на ARM) нужно переписывать, переходим на другой компилятор — опять нужно всё переписывать.









Программная модель для GPU называется SIMT (Single instruction, multiple threads). Одна инструкция синхронно исполняется в нескольких потоках. Этот подход можно считать развитием SIMD. Скалярная программная модель скрывает векторную суть машины, автоматизируя и упрощая многие операции. Именно поэтому для большинства программистов писать привычный скалярный код на SIMT проще, чем векторный на чистом SIMD.
CPU и GPU по-разному решают вопрос латентности инструкций при исполнении их на конвейере. Латентность инструкции – это через сколько тактов следующая инструкция может воспользоваться её результатами. Например, если латентность инструкции равна 3 и CPU может запускать 4 таких инструкции за такт, то за 3 такта процессор запустит 2 зависимых инструкции или 12 независимых. Чтобы избежать такого существенного простоя, все современные процессоры используют внеочередное исполнение инструкций. В этом случае процессор в заданном окне CPU анализирует зависимости инструкций и запускает независимые инструкции вне очереди.
GPU использует другой подход, основанный на многопоточности. У GPU есть pool потоков. Каждый такт выбирается один поток и из него выбирается одна инструкция, которая отправляется на исполнение. На следующем такте выбирается следующий поток и так далее. После того, как из всех потоков в pool была запущена одна инструкция, возвращаемся к первому потоку и т.д. Такой подход позволяет скрыть латентность зависимых инструкций за счёт исполнения инструкций из других потоков.
При программировании GPU можно условно выделить два уровня потоков. Первый уровень потоков отвечает за формирование SIMT. Для GPU NVIDIA – это 32 соседних потока, которые называются warp. Известно, что SM для Turing поддерживает 1024 потока. Это количество распадается на 32 настоящих потока, в рамках которых организуется SIMT исполнение. Настоящие потоки могут в один момент времени исполнять разные инструкции, в отличие от SIMT.
Таким образом, стриминговый мультипроцессор Turing – это векторная машина с размером вектора 32 и 32-мя независимыми потоками. Ядро CPU с AVX – это векторная машина с размером вектора 8 и двумя независимыми потоками.
Концепция магазина образов FPGA
Создание эффективно работающего FPGA-образа для определенной прикладной задачи — достаточно трудоемкая и длительная по времени задача. У хорошо слаженной команды на программирование образа может уйти до пары месяцев, а менее опытные клиенты потратят гораздо больше времени, а то и не справятся с этой задачей вообще.
Поэтому сама собой напрашивается концепция магазина образов, — по аналогии с существующими магазинами приложений для таких платформ как MacOS, Windows или Android. Разработчики могли бы передавать туда работоспособные образы, созданные ими для различных задач, а клиенты — приобретать их для загрузки на свои серверы с FPGA-ускорителями, если эти образы соответствует вычислительным задачам в их проектах.
В компании Selectel в 2018 году начата работа над созданием подобного магазина образов FPGA, которые можно было использовать на арендованных серверах Selectel с этой технологией. Тем самым, для клиентов значительно ускорился бы цикл разработки для новых проектов, а сами программисты (авторские коллективы) получили бы определенный доход от ранее проделанной работы, плюс были бы защищены от пиратского распространения образов по рынку без их согласия.
Полезная ссылка:
DirectX 12
Как уже было сказано в самом начале статьи, с выходом Windows 10 для разработчиков компьютерных игр стал доступен DirectX 12. С подробным обзором этого API вы можете познакомиться здесь. Архитектура DirectX 12 окончательно определила направление развития современного геймдева: разработчикам стали необходимы низкоуровневые программные интерфейсы. Основная задача нового API заключается в рациональном использовании аппаратных возможностей системы. Это и задействование всех вычислительных потоков процессора, и вычисления общего назначения на GPU, и прямой доступ к ресурсам графического адаптера.
Windows 10 только-только появилась. Однако в природе уже существуют приложения, поддерживающие DirectX 12. Например, компания Futuremark интегрировала в бенчмарк подтест Overhead. Данный пресет способен определить производительность компьютерной системы, используя не только API DirectX 12, но и AMD Mantle. Принцип работы API Overhead прост. DirectX 11 накладывает ограничения на количество команд отрисовки процессора. DirectX 12 и Mantle решают эту проблему, обеспечивая возможность вызова большего числа команд отрисовки. Так, во время теста выводится все большее число объектов. До тех пор, пока графический адаптер не перестает справляться с их обработкой, а FPS не упадет ниже 30 кадров. Для тестирования я использовал стенд с процессором Core i7-5960X и видеокартой Radeon R9 NANO. Результаты получились весьма интересными.
Обращает на себя внимание тот факт, что в паттернах, задействующих DirectX 11, изменение количества ядер центрального процессора практически не влияет на общий результат. А вот с использованием DirectX 12 и Mantle картина меняется кардинальным образом
Во-первых, разница между DirectX 11 и низкоуровневыми API оказывается просто космической (где-то на порядок). Во-вторых, количество «голов» центрального процессора существенно влияет на итоговый результат. Особенно это заметно при переходе от двух ядер к четырем и от четырех к шести. В первом случае разница достигает практически двукратной отметки. В то же время особых отличий между шестью и восемью ядрами и шестнадцатью потоками нет.
Выводы
Приложений для тестирования видеокарт достаточно много, они разнообразны, основаны на разных алгоритмах и API, каждая обладает своими особенностями и функционалом, поэтому универсального решения для всех случаев не существует.
Каждый волен выбирать себе приложение для собственных нужд.
Если хотите сравнить производительность своей карточки (в том числе на мобильном девайсе) с мощностью иных, лучше всего прибегнуть к помощи 3DMark.
Для определения стабильности видеоускорителя в режимах предельной нагрузки лучше подойдёт OCCT для DirectX и FurMark для API OpenCL.
Остальные утилиты, в том числе не вошедшие в наш обзор, мало чем отличаются от рассмотренных.
В заключение
Давайте суммируем всю полученную информацию. Каким же должен быть идеальный центральный процессор для игрового компьютера? Во-первых, он должен иметь минимум четыре потока. Как показало тестирование, технология Hyper-Treading в Core i3 реально способствует увеличению количества кадров в секунду. Если мы говорим о процессорах Intel, то золотой серединой являются модели Core i5. При этом несколько игр продемонстрировали, что они неплохо оптимизированы под работу с 6- и 8-ядерными «камнями». Почему именно Core i5? К сожалению, разница в цене между четырехъядерным Core i5-6600K и шестиядерным Core i7-5820K составляет ни много ни мало 147 долларов США, а разница в быстродействии в играх — единицы процентов.









Если мы говорим о процессорах AMD, то для видеокарт верхнего уровня Middle-end, а также High-end потребуется только 8-ядерный чип FX-8000/9000. В то же время в бюджетном сегменте 4-ядерные модели AMD (A8, Athlon X4) выглядят предпочтительнее двухъядерных Intel Pentium/Celeron. В среднем и высоком диапазонах наблюдается обратная ситуация. Здесь заметно превосходство процессоров Intel.